When your data model means something else
One of my coaching clients was designing a program, and came to me with a data-modeling question. The program was for making interactive stories like those Choose Your Own Adventure books. A story contained many passages. In a passage, you might encounter a monster, and then flip to page 62 to fight it, or to page 187 to run away.
He had been choosing between two models. In one, the story contains a list of passages. In the other, each passage has a reference to a story. Which was better?
They have differences in which operations they make easier or more complicated. But I told him that, before even discussing this, or looking at third alternatives: there’s a basic question to answer first:
Do they even represent the same thing?
To see the answer, scroll past this code.
Option 1:
|
Option 2:
|
Story:
title: String
passages: Passage[]
Passage:
title: String
content: String
links: Passage[]
|
Story:
title: String
Passage:
title: String
content: String
links: Passage[]
story: Story
|
I smiled as I gave my answer: They are equivalent if passages are immutable, but different if they are mutable.
Identity
At first glance, both options seem identical. Option 1 says that a story has many passages. Option 2 says that every passage is associated with a story. It’s a one-to-many-relationship.
Or is it? It’s pretty obvious in Option 2 that no passage can be associated with two stories. But they can be in Option 1 —in the mutable case only.
Why not in the immutable case? You might think that you can create an immutable passage, stick it in two stories, and presto — sharing! But, in the immutable world, one copy used twice is the same as two independent copies.
Think about what happens when you go to implement the “edit passage” screen. In the mutable world, you modify the title and content in-place, and it gets updated in both stories. But in the immutable world, modifying the passage really means making a modified copy, and updating it into the story. It’s copy-on-write. To modify the other story similarly, you’d have to go find it and do the same operation to its passage. It really is a separate copy.
What we’ve seen is a fundamental concept in programming: mutable values have identity. And immutables don’t.
With immutable values, there is no notion of “the same” story or passage beyond “these two have the same values.” There is no way to distinguish between two stories that have the same passage, vs. two stories that have identical copies of the passage. There is no true sharing.
With mutability, the opposite holds. If there are two passages that have the same values, and updating one also updates the other (i.e.: all reads and writes are identical), then they really are the same. Conversely, it’s now possible to have two identical passages which are not the same.
So, the mutable vs. immutable debate is not just about in-place updates vs. modified copies. Immutability means independent parts. Mutability means sharing.
One way to model this is to think of every mutable value as really a pair. The first element of this pair is the value itself. The second element is a magic “token,” created at allocation-time, which is guaranteed to be distinct from every other such token in the program. This explains why, if you do want proper sharing in the immutable world, you’ll need to change your data model to explicitly add some kind of identifier. This, by the way, is one of the reasons why it’s correct to think about immutability as the default, and mutability as an added feature.
Bigger Differences
In the example above, there’s a simple fix if you like Option 1, but you don’t want sharing between stories: Add an extra rule, or invariant, forbidding sharing. Every rule means extra work to enforce, but this one should be easy. And you still have the option to just not care about sharing.
But adding mutability can mean more pervasive changes to a data model. Here are two more options for passages and stories, in stripped-down form. In Option 3, the story has a start passage, and every passage has a number of successors. In Option 4, we store the edges in reverse, with each passage having a parent.
Option 3:
|
Option 4:
|
Story:
start: Passage
Passage:
links: Passage[]
<content>
|
Story:
passages: Passage[]
startIdx: int
Passage:
parent: optional<Passage>
<content>
Extra invariant:
Every passage is reachable from the start passage
|
If you squint at it right, when passages are immutable, these are the same. Option 3, naturally, represents trees (no cycles). But, by reversing the arrows, any tree can also be turned into the form of Option 4, so Option 4 also represents trees. This is a convenient lie up until you have to implement any kind of editing, and find that it’s just pretending to be a tree: you’ll need to rebuild large sections on every edit.
Option 3, immutable
|
Option 4, immutable
|
 |  |
But, after adding mutability, Options 3 and 4 become unequivocally not the same. When passages have identity, Option 3 now represents arbitrary graphs with ease. Option 4, meanwhile, now represents these weird graphs that can have cycles, but where every passage can only have one predecessor. Picking between models goes from a game of “which one is more convenient to use” to “which one actually represents a story?”
Option 3, mutable
|
Option 4, mutable
|
 |  |
Reversing the Polarity
We’ve seen two examples where adding mutability suddenly made two data models different. Is there a case where the story is reversed, and mutability can make two different models the same?
At first I thought there wasn’t — making things mutable just adds distinctions. We need the reverse. But for any rule about data structures, you can often get a reverse rule by putting the data structure in a “negative position” — that is, as the argument to a function, or as the key to a map. So consider options 5 and 6, this time representing just passages:
Option 5:
|
Option 6:
|
Passage:
title: string
content: string
summary: string
|
Passage:
title: string
content: string
Global:
summary: Map<Passage, string>
|
Here, we want to track some extra information on a passage. Perhaps you want to add some auxiliary information like the Chinese translation or a summary. Or perhaps you want to compute some property of all the passages, like how many steps till the end of the story, and you need to cache the intermediate results. The most straightforward way is adding an extra field. But another approach is to create a hashmap elsewhere associated each passage to some extra data. This pattern is often necessary when extending third-party APIs. And it only works when the objects are mutable.
Option 5 is always straightforward: each passage gets an extra string. But with immutable passages, Option 6 has an extra restriction: there cannot be two passages with the same title and content, but a different summary. Database people call this a functional dependency.
Perhaps you can hack it by making the map check for pointer-equality anyway, but chances are you’re breaking the assumptions of the rest of your code. Immutable code usually moves and copies objects willy-nilly, meaning that “the same object” will have different memory addresses over time.
On the other hand, when passages are mutable, you can think of every passage as coming with a magic token that distinguishes it from others with the same values. And so, that hashmap really does just mean that every passage gets some extra data.1
In software design, the first step is to discover the essence of the concepts you are implementing. I wrote in the first paragraph that a story contains many passages, so the basic idea is that a story contains passages, right?
Too fast. Since it makes sense to speak of a passage without a story, neither direction is more primitive. The primitive idea is just that the one-to-many relationship exists. If you were modeling stories in a database, the standard approach is to have a table just for storing the stories-passages relationship, separate from the tables for stories and passages. You can get the passages for a story, and the story for a passage. The relationship knows no direction.
How do you express this in a program? In 1987, a researcher at General Electric came up with an idea for a new style of programming in which relationships between objects can be created and manipulated as easily as the objects themselves. There’s been an uptick in the past decade, but first-class relationships still haven’t caught on even in the research world, and so I promise your language doesn’t have them. We can’t put the idea of a story-passage relationship directly into the program. We have to make do.
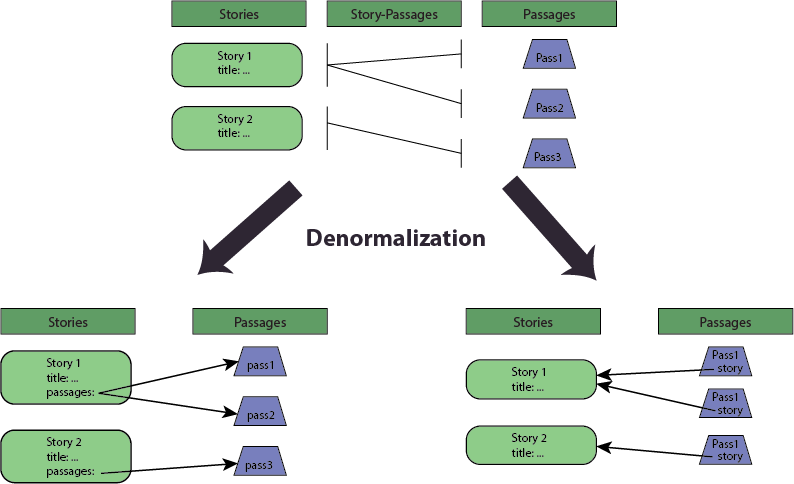
In databases, when you find yourself often using something in one table to look up things in another, you can speed things up by denormalizing the structure, fusing two tables together. In one possible denormalization, you fuse the Story-Passages table into the Stories table, giving each story a list of passages. In another denormalization, you fuse the Story-Passages table into Passages, giving each Passage a reference to its containing story. The two denormalizations correspond to the original Options 1 and 2 at the top of this post. (A third denormalization fuses Story-Passages into both.)
And now, we see that the reasons to choose one over the other are the same as the reasons to denormalize a table. For the choice between the passages and the story fields, it’s a matter of how often each would be accessed. Since data tends to be accessed hierarchically, I’d expect the need to fetch all the passages of a story to be great, and the need to work with a passage of an unknown story to be slight. This suggests Option 1 (well, Option 1 + more fields you need to actually write this app). But know that both are denormalizations of the true relationship.
Edit 7/25/2018: Shortly after writing this, Daniel Jackson told me about OMT, an old method for object-oriented design. OMT (or at least Daniel) also argues that it is proper to think in terms of relationships rather than hierarchy ("objects as points rather than containers"), and these relationships have no direction other than those that make data-access patterns easier.
Building Blocks
What about mutability gives values identity? How does it make two things of equal values suddenly inequal? Let’s dig into the mechanics of equality and find out.
Equality in programming languages comes from the idea of identity of indiscernibles , which states that if there is nothing you can do to tell two things apart, they are the same.
At their core, Story and Passage are both tuples. In Option 1, Story is a pair of a title and a list of passages, while Passage is a triple of a title, contents, and a list of links. At the end of the day, the only thing you can do with a Story or Passage is to look at its components. So if both components of two Story's are equal, then the Story‘s are indistinguishable, and hence equal.
This generalizes easily to arbitrary pairs, and then arbitrary tuples. We can formalize that into a rule, like this:
This is the eq-pair rule, which defines equality for pairs exactly as we said above. You read this as “if the conditions on the top are true, then the statement on the bottom is true.” So this says that, if the corresponding components of two pairs are equal, then the pairs themselves are equal.
How does this change when one of those components, e.g.: the list of passages, is mutable?
First, let’s talk about mutable variables. When you make a mutable variable like in “int x = 1,” you should think of those as happening in two steps. First, you create a location in memory that can change, and initialize it with the value “1”. This location is called a mutable reference cell. You then assign this reference cell to the variable x. Variables are immutable containers that hold mutable reference cells.
In languages like OCaml/SML and Haskell, it looks exactly like this: you create a mutable reference cell using the ref or newIORef command, and store it into an immutable variable. This distinction is also apparent in languages like modern JavaScript and Scala, which have separate keywords (JS: let/const ; Scala: var/val) for mutable and immutable variables: mutable variables act like immutable variables containing mutable objects. Yet even in C and Java, the execution works like this. When a program is compiled, there will typically be a memory slot on the stack containing a value that changes, and the variable itself, which is always “stack pointer + 16.” The difference between these is the difference between call-by-value and call-by-reference.
So, if Passage’s are mutable, when comparing two Story’s, we are not comparing a title and a list of Passage’s; we are comparing a title and a list of mutable reference cells.
Mutable reference cells can be thought of as an “address” which refers to some location in the heap. The address and heap usually wind up being a pointer and main memory, but this definition is abstract, and you can also implement it as a hashmap. To dereference a cell, you look up that address in the heap, return the value, and keep the current heap the same. Here’s a rule that says that:
By the way, while this exact rule is specific to a handful of simple programming languages, the underlying idea is universal. In every language, when you write down what it means to look up a mutable variable, you’ll get something very close to this rule.
So, equality: Once it’s created, the only things you can do with a mutable reference cell are read to it and write to it. Following again the principle of Identity of Indiscernibles, two mutable reference cells are equal if and only if every read and write is the same. If two cells are equal, and you write a value to one of them, you better be able to read it from the other. This means that equality of addresses is trivial: every address is equal to itself (and nothing else).
So, the interesting part is in where these addresses come from when reference cells are created. In every language, the semantics look like this:
In English: to create a new reference cell with initial value v, you find an unused address a in the heap, and set the value at that location to v. The new reference cell is represented by that address a.
That top condition “a is a fresh address” is the magic. That condition provides the global property we need: that the address a is different from the address of every other mutable reference cell. Otherwise, it could confuse different cells. This means that, if two reference cells are equal, they were created by the same call to newRef. Or: If two mutable Passage’s are equal, they were created by the same constructor.
Ergo, it’s the magic token that gives mutable values their identity.
Everything we’ve discussed about mutable values having identity boils down to this one rule. Yet this one rule has deep implications about what your data means. So much of software design reduces to just understanding these building blocks.
Liked this post? There are still some slots open in my Advanced Software Design Weekend Intensive, happening in San Francisco the weekend of July 28th.
Update 9/17/2018: See the comments for some discussion of how to make it impossible for the passages of one story to link to those of another story.
AcknowledgmentsThanks to Dhash Srivathsa and Tikhon Jelvis for comments on drafts of this post.
1 This is where it matters that pointer-equality is actually just an approximation of equality for mutable values. When you actually implement this, you might get (and I have actually gotten) bugs due to the ABA problem.

"But for any rule about data structures, you can often get a reverse rule by putting the data structure in a “negative position” — that is, as the argument to a function, or as the key to a map."
ReplyDeleteThen why wouldn't you back off the conclusion that it is "correct to think about immutability as the default, and mutability as an added feature."?
Great article BTW.
Hi Chase!
DeleteThese are two pretty general orthogonal statements.
The classic example of the "rules flip in negative position" rule of thumb is subtyping. Say you're deciding whether you can replace one function with a "more specific" function. If function A is "more specific" than function B, then it could be the case that the arguments to function A are actually more general! I just Googled for an explanation; here's something I found: http://tomasp.net/blog/variance-explained.aspx/
So, basically what it means here, is: if the "magic token" of mutable identity is an argument vs. a return type of a function, then it has opposite effects on the surrounding parts of the program.
To elaborate on "mutability is an added feature":
When you develop a programming language formally, you start with the pure lambda calculus, which is immutable. You get mutability by adding a construct for mutable reference cells, and a couple rules to express their semantics. Mutability is a feature just like tuples, functions, etc.
My immediate thoughts, when seeing Option 1 and Option 2, were:
ReplyDelete- Each Passage in Option 2 links to a Story *and* other Passages. Hence PassageA for StoryA can link to PassageB for StoryB, PassageC for StoryC, etc. These seems like invalid/illegal states to me.
- Such arrangements are not possible in Option 1, since Stories are not reachable from Passages.
Hence Option 1 is preferable, since we should "make illegal states unrepresentable". In other words, the space of values in Option 2 is "too big", and we would need to take care that we don't violate the single-story invariant by accident.
Good insight, Warbo. And you're totally correct about making illegal states unpresentable, which is the first half of my Representable/Valid Principle (one-to-one correspondence between representable and valid states).
DeleteBut here's a kicker: If passages are mutable, then there can be no well-defined notion of a passage belonging to a story. Two stories containing the same passage is indistinguishable from two stories containing exact copies of that passage.
And in the mutable case, it's not much better. Here, this is a notion of “belongs-to.” In option 1, a passage belongs to a story S if it’s in the S.passages array. In option 2, a passage P belongs to P.story. But, in both cases, there is nothing stopping a passage from linking to passages in other stories!
I don't have a proof yet, but, I'm pretty convinced that, with this kind of type system, you cannot guarantee that two graphs are disjoint without needing some kind of extra invariant outside the type system.
All is not lost though: you can do this using existential types.
It works like this: Imagine you had only two stories, S1 and S2. You could have different types for each of their passages, types P1 and P2. Guaranteeing no pointers from passages of S1 (type P1) to passages of S2 (type P2) is now trivial.
But you can have arbitrarily many stories, so you need an infinite family of types. Call it “GStory s”, where “s” is a parameter. What value should “s” take? It should be a different type for every story: you need to create them. This is a type-system feature called “dynamic generativity.”
Here’s an example interface:
type GPassage s = { links :: List[GPassage s], ….}
type GStory s = {name :: String, passages :: List[GPassage s] }
type Story = exists s. GStory s * {makePassage :: String -> GPassage s, addPassage :: GStory s -> GPassage s -> unit, …}
You can think of this as: whenever you create a new story, the type system creates a new type-level token “s.” A passage can only be in a story, and a passage can only link to another passage, if they share the same type token. So, there can be no connection from one story to the passages of another story.
The Haskell uses the exact same technique in the ST monad, to guarantee that all operations run on the same “thread.”
BTW, I generally do not recommend doing this except when the risk is high. While a lot of ways to follow the Representable/Valid Principle make your representation more precise and your code cleaner, adding type-level tokens can only add complexity. It’s still helpful to understand how it works and to have it in your toolbox.